




Data Sovereignty Unveiled – Balancing Rights, Privacy, and Innovation
In this episode of the Beyond Data podcast series, Tessa Jones (Calligo’s Chief Data Scientist) and Peter Matson (ML Solution Architect) are joined by Martin Hoskin, Chief Technologist at VMware and Advisory Board Member for the Centre for Data Ethics & Innovation. In this enlightening discussion, we delve into the concept of data sovereignty and its implications for ethical data use, as well as explore how federated learning offers a promising solution to the challenges we face.
Understanding Data Sovereignty
Data sovereignty encompasses the notion of data residency, access control, and governance. The dominance of American cloud providers, subject to U.S. laws, raises concerns about data privacy and security, particularly in the European context. For certain organizations, like government agencies and defense suppliers, data sovereignty becomes a critical factor. VMware has introduced a program to certify partners as Sovereign, ensuring data storage, processing, and governance are specified, differentiating them from major hyperscale cloud providers.
The Challenge of Data Sharing
Data sovereignty also touches upon the ethical dilemma of sharing data for legitimate purposes like law enforcement investigations. Striking a balance between data privacy and the greater good is complex. For instance, the case of Apple’s cloud security raises questions about when governments should access personal data to combat serious crimes.
Federated learning emerges as a promising solution to data sharing challenges. This approach enables entities to collaboratively train machine learning models without sharing raw data. Instead, local models are trained on separate datasets, and only aggregated model updates are shared with a central server. This preserves privacy and protects sensitive data, making it suitable for applications like fraud detection in the banking industry.
Experimenting with Federated Learning
The Centre for Data Ethics & Innovation (CDI) conducted an experiment using federated learning for government-provided services. The CDI set up two data sets—one for detecting fraud in financial transactions using SWIFT data and another for studying the spread of COVID-19. The experiment highlighted the complexities of sharing data, including obtaining government buy-in and ensuring data anonymization to protect privacy.
While federated learning is ingenious, it comes with its own set of challenges. Concerns arise about the aggregator potentially being reverse engineered to extract sensitive information. Additionally, the scale of data involved in real-world applications may make reverse engineering even more difficult.
As data continues to play a critical role in various industries, addressing data sovereignty and privacy concerns remains paramount. Federated learning offers a way to enable collaboration without compromising data privacy. However, continuous innovation is necessary to tackle challenges like reverse engineering and fully realize the potential benefits of this approach.
Ethical Considerations in AI and Data Technology
The conversation takes a broader turn, exploring the intersection of AI, data, and ethics. AI development should consider risks, probabilities, and potential biases to build robust and ethical systems. Ethical implications of sharing genetic data and the responsibility of pharmaceutical companies in handling such information are discussed.
Regulating AI Ethics and the Divide between Academia and Industry
The need for clear regulations to define and enforce ethical standards in AI and data technology is acknowledged. Balancing philosophical academic perspectives with industry practicality becomes essential as AI progresses toward stronger AI with self-learning capabilities.
Navigating Legal Frameworks and Data Sharing in Healthcare
Enforcing ethical standards and regulations on a global scale, especially with rogue states, poses challenges. Collaboration through global forums, like Gaia X, can facilitate trust, data security, and individual interpretations of frameworks. Standardized data-sharing frameworks and data portability regulations can address data sharing challenges in healthcare.
Autonomous Weapons and the Role of Global Forums
The ethical challenges of deploying AI in autonomous weapons, especially in making life and death decisions, raise profound moral dilemmas. The hosts stress the importance of engaging in public discourse and involving the global community to shape AI and robotics’ future.
The Impact of Social Media on Data Privacy
The podcast concludes with a discussion on the influence of social media on data privacy and the ethical considerations surrounding its use. Addressing the impact on young minds and the potential implications on decision-making, including voting rights for 16- and 17-year-olds, is highlighted.
In conclusion, data sovereignty, AI ethics, and federated learning are crucial components of an evolving data landscape. Ethical considerations must be at the forefront of AI development and data sharing to ensure responsible and equitable data-driven futures. By embracing ethical practices and fostering interdisciplinary collaboration, we can harness the potential of AI while respecting individual rights and privacy. Establishing global forums and transparent public discussions will play a pivotal role in shaping the future of AI and robotics in a manner that benefits humanity as a whole.
Listen on Spotify or watch below

Making complex data available for the benefit of society
In Calligo’s latest Beyond Data podcast, Tessa Jones (Chief Data Scientist) is joined by Dr Ellie Graeden, Research Professor (Center for Global Health Science and Security) at Georgetown University. Here we explore some of the episode’s highlights:
- The inherent conflict of private data and the public good
- Protecting individual rights within federated learning
- The importance of effective communication and a common language
- Designing systems and policies that work together
- Focusing regulation on outcomes, not creating data siloes
At societal level, poor communication costs lives
Transitioning data across and between departments and data systems has historically been fraught with problems – who owns it? Who pays for it? Is it understandable and translatable into meaningful and actionable insights for the end user?
Having worked extensively in disaster response, Dr Graeden has seen first-hand the potentially life-threatening issues that can arise when government departments’ data platforms produce incompatible outputs:
- If 20,000 people need water, how many pallets need to be shipped?
- If 10,000 electricity meters have been knocked out by a hurricane, how many people need feeding?
In such scenarios, identifying individuals amongst population-level data is crucial if the help provided is to be sufficient.
“We have to be able to really effectively move and communicate and share data that are relevant, in ways that they can get used by people all across the system”
Of course, any data system design should ensure privacy and protection for personal data. ‘Big data’ is still relatively new, and as such more powerful and widespread regulatory controls are now being introduced, although the US still does not have consistent requirements for how data should be handled. Fundamentally, meeting a population’s needs today, and planning for them tomorrow, requires the data of individual people to be analysed. Personal data must be shared quickly, effectively and all the while protecting individual rights. Data system design must therefore:
- Include all players
- Consider cultural constraints
- Keep out bias
- Ensure the right words and phrases are used
- Focus on the ‘so what’, why does it matter?
“Every single thing we experience can be captured as data”
Even the most mundane moments in our daily lives leave a digital footprint, we shed data everywhere. But when does ‘my’ data become public, or the property of the software developer or the service provider? VR headsets collect ephemeral data that is analysed and applied for that one end user, but if that data is assumed to fall under GDPR the potential to use it for positive outcomes is severely limited. For example, should authorities be notified if content viewed and generated is illegal or harmful? And what if that chip can detect if the user is having a stroke, is that data classified as ‘health’ data? Can it be used to alert the individual to their medical emergency without contravening legislation? What if your mouse clicks can detect the early stages of Parkinson’s? Should you, could you, be told?
“If you’re treating this data as health data, then they have a very different set of regulatory constraints. HIPAA isn’t going to regulate those because it’s not a health care provider or a health insurer”
Piercing the veil
The conflict between personal protection and public good is everywhere, and Dr Graeden believes that some new data laws will create problems for federated learning. Legislation has clear boundaries (speed limits, blood alcohol levels) whereas science deals in spectrums, probabilities and unknowns.
Deleting an individual’s personal data from the model breaks the system, contradicting what regulators are trying to achieve. The solution is to prioritize outcomes, not processes – it doesn’t matter whether you write the rules with a pen and paper, or with AI, as long as you write the rules. Expanding the framework by setting gradients of data availability affords protection for individuals, whilst making data available that informs better decision making for public bodies.
“Data is nothing more, nothing less, than an abstract description of our world. A useful and powerful language that can tell us things that other languages don’t”
Data can no longer exist in siloes if it’s to be useful to society
There is now a healthy global appetite for the discussion around data, thanks in the main to two recent developments:
- Covid gave us huge amounts of data about mortality levels, vaccination rates, hospitalisation trends – all of which were in the public consciousness every day
- AI and ChatGPT – articles and debates about the pros and cons are everywhere, discussion is not just in the scientific community
The key challenges now for data scientists are expectation management and communication – we need to be clear about aims and specific about context, as well as knowing what to leave out to avoid overwhelm and misunderstanding. Unfortunately, scientists are not always great communicators (using complex terminology and detail, rather than common parlance and generalization) as Covid demonstrated:
- Did having a vaccine mean you wouldn’t get sick? Or just less sick?
- ‘Everyone should wear a mask’ became ‘wear a mask if you can’. This was due to limited supply, but it appeared that the science was not clear
“The scientific approach means you never have an answer… we are trained as scientists to focus on the fact that we don’t know”
In fact, the only answer is that the right data, used consistently and communicated clearly, will always allow us to be prepared, not reactive. To make decisions for the public good that protect every individual.
You can find out more about the common language of privacy in our Rosetta Stone eBook.
You can also watch Tessa’s fascinating podcast with Dr Graeden below.

AI bias is frequently failing the LGBTQ+ community
In our latest Beyond Data podcast, co-hosts Sophie Chase Borthwick (our Data Ethics & Governance Lead) and Tessa Jones (our Chief Data Scientist) invited Tomer Elias, Director of Product Management at BigID, to discuss how AI bias affects the LGBTQ+ community.
Here we explore some of the episode’s highlights – although you can also watch the full episode here.
Why is there bias?
When building an AI algorithm or AI solution, it is crucial to make sure it’s based on data sets that are both unbiased and diverse and, in terms of the LGBTQ+ community, this often falls short. Whatever the sector – work, health, entertainment – all will be subject to bias if the LGBTQ+ community is not taken into consideration when an AI solution is being created.
For Tessa Jones, one of the barriers to collecting sufficient data is that people might be reluctant to share information about their sexual orientation or their gender journey – particularly if they don’t know how this personal data will be used. Sophie Chase-Borthwick agrees that it quickly becomes a catch-22 situation:
“The biases that make you nervous of disclosing information are the very reason that you need to disclose said personal information in order to prevent bias and improve.
Knock-on effects
Drawing on his experience as a board member of an organization that supports LGBTQ+ employees, Tomer Elias explains how candidates are being let down by recruitment AI solutions and that the consequences are significant.
“A lot of people in the LGBTQ+ community are unemployed and that’s not because they’re lacking the professionalism and passion.”
Meanwhile, medical advances in the LGBTQ+ community are constantly evolving, and many algorithms do not take these changes into account.
“People who are transitioning are not getting the right treatments because the treatment providers are not well educated about it and the data is not diverse enough,” explains Tomer.
Tessa also raises the issue of health apps that require a user to state whether they are male or female.
“Even though the equations could be written differently to how you use different input, they’re just not and that means, you either have to pretend you’re something different or just not use that tool.”
Potential of AI to help overcome bias
While AI bias is clearly affecting the LGBTQ+ community, there are innovative ways it can be used to overcome it, too. Such as in recruitment.
“At the initial interview stage, AI could be used to scramble the voice so you would not know if the candidate was male or female or someone who has transitioned,” says Tomer.
He also poses the possibility for AI to help with the retention of LGBTQ+ employees.
“Technology could help employers know that the employee is happy and feels a part of the organization.”
Time to step it up…
There are already many AI forces for good – including recommendation systems which can help LGBTQ+ people feel more emotionally supported and The Trevor Project that uses AI to predict which callers are more likely to commit suicide to ensure they get help.
Much more needs to be done. But the fact that people are starting to think about AI bias and the LGBTQ+ community is a step in the right direction.
“Now we’re talking about it and people are realizing the actual real-world implications, hopefully more people will feel comfortable expressing themselves and we can close some of that data gap so there is more information for the models to work off,” according to our Data Ethics & Governance Lead, Sophie Chase-Borthwick.
“It’s also super critical that we have diverse AI developers who are knowledgeable about people and bias,” adds Calligo’s Tessa Jones.
To hear more of our fascinating discussion on AI bias and how it affects the LGBTQ+ community, tune in to our latest Beyond Data podcast episode below.
The Jersey Transform 2022 Event
The Channel Islands’ Premier Data & Cloud Strategy Event
Join The Channel Islands’ Premier Data & Cloud Strategy Event – Transform 2022
Our speaker line-up includes Professor Hannah Fry, a Professor in the Mathematics of Cities, science broadcaster, and winner of the prestigious Zeeman Medal.
- Venue: The Royal Yacht Hotel
- Location: Weighbridge Pl, St Helier, Jersey
- Date: 30th November 2022
- Timings: Conference from 1.30 pm-5 pm, cocktails and canapes from 5.30-7 pm
Please Note: This event is for business leaders, and spaces are therefore limited.
To secure your exclusive place, register here.
Join your peers from across the Channel Islands and get past the buzzwords to learn more about what Business intelligence (BI) really means in today’s modern businesses and why this is a strategic imperative for leadership teams and not just your IT teams.
You will learn about Data and how to unlock its true power, covering:
- The trends in Cloud technology and the business advantages to be gained from them
- Why the Cloud is the foundation to becoming a truly data-driven business
- Best Data practices to help organisations make better decisions
- Using accurate Data to drive change and grasp opportunities quicker
- Eliminate risk and inefficiencies
- Adapt quicker to market challenges

The dark side of AI energy consumption – and what to do about it
Artificial Intelligence’s ability to augment and support progress and development over the past few decades is inarguable. However, when does it become damaging, contradictory even? In our latest Beyond Data podcast AI’s Climate Jekyll & Hyde – friend and foe, Tessa Jones (our VP of Data Science, Research & Development) and Sophie Chase-Borthwick (our Data Ethics & Governance Lead) discuss exactly this with Joe Baguley, Vice President and Chief Technology Officer, EMEA, VMware.
Our speakers explore the multifaceted topic of energy consumption and AI – from whether all applications are equal for energy consumption (or reflecting if there are some ‘better’ than others), to creating visibility and responsibility of energy consumption for all stakeholders. Here we try to give clarity to some of the grey areas that were discussed.
Should we consider all applications equal?
“AI and machine learning are about huge things, huge data sets, huge computation actions … all of those have huge implications in terms of energy,” Joe observes, before dropping in hugely sobering stats such as the total annual energy consumption of bitcoin being the same as Norway. Even when considering the often-touted argument of 57% of the energy for bitcoin mining using renewables, Joe counters: “But those renewables could have been used for something else, right? Those solar panels… and those hydropower stations and those wind turbines, we could be using them for something else.”
This raises the ethical question of whether there should be stricter governance, standards, and precedent set on more ‘moral’ applications for their energy consumption. Should we be more closely considering the difference in energy consumption between server farms that support minimizing food waste versus those that are focused on mining digital currency, for example?
“Is there an opportunity for [greater] regulation?” Tessa ponders. Would this regulation help challenge the current status quo for all applications’ energy consumption being considered equal? While Sophie observes: “We’ve had certain European nations start to put rules around data center expansion, where you’re allowed and not allowed to build because of the capacity there, which isn’t regulating the use of it. But it does have that knock-on effect that if you literally can’t build the data center support, you have to start thinking about other ways to build [models].”
When considering Sophie’s point on alternative ways to build models, Joe notes: “We’re using AI to deal with the symptoms, but maybe there’s some better ways we could be using AI to deal with the cause as well”.
And this all raises the next question – who should ultimately be making these ongoing moral calls for the environment and energy usage?
Embedding Environmental, Social, and Governance (ESG) by design
Environmental, Social, and Governance (ESG) is shorthand for a framework that helps stakeholders understand how an organization is managing risks and opportunities related to environmental, social, and governance criteria. Our speakers untangle the idea of ESG and how companies could use it to help triage the different applications they use.
Joe asks: “Is there an ESG-led marketing opportunity here? Your AI might be the same as my AI, but my AI is better from an ESG perspective. They both get the same results at the same time for the same cost, but this one’s better from an ESG perspective, in terms of sustainability, in terms of social good, in terms of environmental.”
By placing more emphasis on ESG as the criterion for measuring impact and success, it could help with embedding sustainability in the heart of the application’s deployment, rather than a siloed approach. Sophie agrees: “We have privacy by design, we have security by design. Why not have ESG by design?”
Following on from this thought, our speakers consider the cost implications of AI and ESG with Joe observing, “There’s a lot of businesses right now that can’t afford AI because it’s expensive…but I believe they will come to a tipping point where they can’t afford not to”.
Are we over-prioritizing accuracy?
“There’s a hyper-focus on the accuracy,” according to Tessa. “It ends up not even being about the motivation for green, it’s a motivation for fast training, fast tuning. Unfortunately, it’s how most data scientists are motivated; be faster without having to compromise their accuracy.”
Often, the increase in accuracy can be mapped on a logarithmic graph. Good gains at first, but quickly tapering off to minimal increase. Is it useful to be that much more accurate, often by points of a decimal? “Some are good, more must be better … people just keep going, as opposed to saying actually good enough is good enough,” Joe summarizes.
Instead of chasing marginally better accuracy each time, we should be considering the application in a holistic view. The increase in accuracy might be 0.01%, but would cost heavily for energy consumption – is it worth it? Should we be better at exposing these costs more vigorously throughout a team so everyone can feel more empowered and have the visibility to interrogate more closely?
To hear about how our speakers untangle these controversial questions and more, tune in now to Beyond Data podcast episode 3: AI’s Climate Jekyll & Hyde – friend and foe.

Vehicle Autonomy; the good, the bad, and the complicated
In our second Beyond Data podcast episode ‘Autonomous mass transportation and its impact on citizen privacy’, we will sit down with Beep’s Chief Technology Officer, Clayton Tino to explore the current landscape of autonomous vehicles (AVs), whether AVs truly can replace the human factor in public transportation, and how AV ethics can be holistically measured. Here we give you a snapshot of that fascinating discussion by digging into a few of the explored topics.
You can watch episode 1 here
When looking at AV ethics, there are two strands to consider:
1: The ethics programmed into the AV itself (e.g., how the AV ‘decides’ which course to take when it identifies a hazard, otherwise known as the ‘trolley car’ scenario).
2: The ethics surrounding embedding AVs into society (e.g., whether we can truly replace the human factor in AVs, or what level of surveillance AVs should have).
Going beyond the trolley car scenario
Often touted as the litmus test for AV ethics, the ‘trolley car’ or ‘trolley problem’ is a thought experiment where someone chooses between saving five people in danger of being hit by a runaway trolley by diverting the trolley to hit one person. This is extrapolated to AVs by using a scenario such as an AV traveling down the street when suddenly a group of pedestrians runs out. The AV must ‘choose’ between hitting the group or altering its course but by doing so, hitting a lone pedestrian.
The ‘Moral Machine’ experiment was an online survey of 2.3 million people worldwide that investigated the moral dilemmas faced by autonomous vehicles. The study found that moral principles guiding drivers’ decisions varied from country to country, and also women and men viewed ethical and moral situations differently. This made something like the trolley problem difficult to quantify and standardize worldwide.
Far from a simple ethics exercise…
On the surface, it seems a simple ethics exercise. But as Clayton Tino summises: “People like to think they have a preconceived notion of how they would behave, but I just don’t buy that. [A near miss] is a purely reactive response. We’re setting unrealistic expectations on the machine because we need to blame something when something goes wrong.” Tessa Jones (podcast co-host) agrees, observing: “AVs need some decision-making process, but I don’t have a decision making process myself.”
As Sophie Chase-Borthwick (podcast co-host) explains: “We expect our AVs to be guaranteed safe. But we know that any other vehicles are not 100% safe with a human behind them. So we have a higher expectation of what ‘safe’ looks like when it’s autonomous [as opposed to] to when it’s a human.”
In our opinion, the disproportionate emphasis placed on the trolley problem to solve the lion’s share of AV ethics is reductive and dangerous to advancing AV technology. It’s a useful piece of the puzzle but it’s a symptom when we should be focusing on fixing the cause.
In our podcast, we also explore the importance of accurate and timely hazard perception (both in humans and AVs). By improving hazard perception, it not only provides safety methods for AVs but can help reduce or mitigate entirely AVs even having to make the trolley problem decision in the first place.
Can we ever truly replicate the human factor?
There are five levels in the maturity of autonomy of AVs – with Level 1 being no autonomy and Level 5 being a vehicle without a driver safely taking you to where you want to go.
For Clayton, Tessa and Sophie the debate centers on where the application of AVs could work best with the least blockers. They wonder whether public transportation seems an ideal choice, given how it could be geo-fenced, fixed route and hyper-local.
However, when considering AVs in the context of public transportation, they realize it’s important to look at the holistic service of public transportation, beyond just the driving. As Clayton pithily observes when considering AVs for school buses, “[Bus drivers] do a heck of a lot more than just drive the bus … they need to be aware of passenger safety and security, assistance…”.
For example, in London, there’s been some disputes between wheelchair users and pram users about who has first access to the space. Bus drivers (and others in charge of public transportation) are expected to act as mediators to settle these disputes. How would this be replicated in an AV with no human factor?
The answer could lie in more secure and closely governed surveillance. Having surveillance on public transport AVs could add a safety layer to minimize vandalism, protect the users and ensure the AVs remain a reliable and safe choice. Our podcasters observe the marked differences between privacy in the US and Europe but with the introduction of GDPR-style laws such as the California Consumer Protection Act (CPPA), there will inevitably be more scrutiny on how the surveillance data is used and stored.
However, as is often the case with autonomy when it comes to public transport there’s no easy decision. By removing the human factor, there need to be other allowances made to fill the gap. Companies and governments need to work hard to make sure both the users and their data are protected and that these allowances do not harm the end-users or misuse them for commercial purposes.
Our podcast delves more into the nuances and pitfalls when considering the commoditization of a public service, such as public transportation. Generally, the people who need it most are vulnerable, and unless there’s a significant level of transparency, can users be fully aware and able to consent to the wider implications of being surveilled?
To hear more about how we untangle and much more, watch our episode on ‘Autonomous mass transportation and its impact on citizen privacy ’.

UPDATE 8: The Data Privacy Periodic Table
By Sophie Chase-Borthwick, Calligo’s Global Data & Governance Lead
From the increasing importance of ethical AI principles, to the EU’s all-encompassing data strategy – including the first law on AI by a major regulator, anywhere – and US President Joe Biden’s new transatlantic data agreement, much has been bubbling away in the world since my previous revision of The Data Privacy Periodic Table.
Here I delve into the whys and wherefores of any changes I’ve made since then – in the form of Update 8.
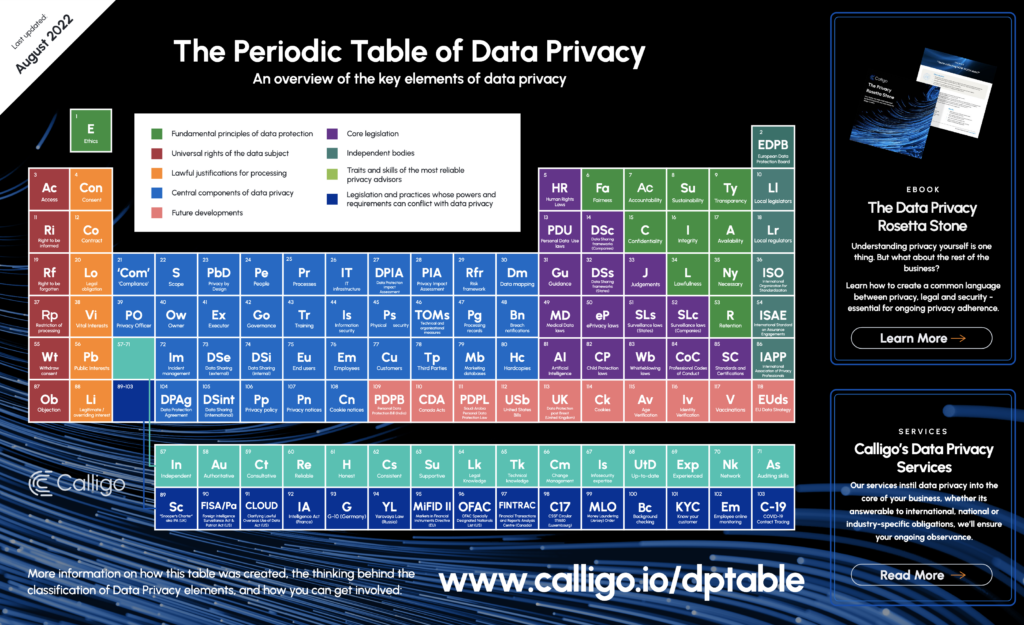
Fundamental Principles of Data Protection – some newcomers…
Acting FAST on ethical AI
6-9

The Alan Turing Institute developed the ‘FAST Track Principles’ to support a responsible environment for data innovation, in particular when understanding Artificial Intelligence ethics and safety. To reflect the importance of ‘ethical AI’ (as demonstrated by the ICO’s collaboration with the Institute) I have added Accountability and Sustainability for the first time.
While Sustainability is the only element that’s really unique to AI, Fairness and Transparency (moved, but not new) have and always will be fundamental to data privacy. I had considered Accountability to be almost too obvious and intrinsic a component of privacy to have its own place. But, as a nod to my opinion that the FAST Track Principles should become industry standards, here it is. After all, FST certainly doesn’t have the same ring to it.
While I can’t go into huge detail here about each one, I urge anyone who hasn’t read up on FAST to do so now – and embed the principles into every aspect of AI project delivery.
“As inert and program-based machinery, AI systems are not morally accountable agents. This has created an ethical breach in the sphere of the applied science of AI that the growing number of frameworks for AI ethics are currently trying to fill. Targeted principles such as fairness, accountability, sustainability, and transparency are meant to ‘fill the gap’ between the new ‘smart agency’ of machines and their fundamental lack of moral responsibility.”
The Alan Turing Institute: Understanding Artificial Intelligence Ethics and Safety
Moved, but not downgraded
34 & 35

Lawfulness and Necessity have made way for FAST. Far from downgraded, they’ve merely moved a little within the same elemental area. But, Relevancy has been removed altogether. In my opinion, this is more than covered by Necessity and there’s no need to double up on similar principles.
Retention becomes the industry norm…
53

We welcome Retention to the table – this echoes the fact that this has become more of an industry standard term.
Highly unstable, yet fascinating Future Developments…
And now for the fast-moving, highly unstable elements: the future developments that are shaping the world’s data privacy parameters and legislation.
US legislation limbo…
112

To the United States and various US Bills – starting with President Joe Biden’s new transatlantic data agreement in principle with the European Union.
We’ve been here twice before – with similar proposals previously thrown out. Although it doesn’t seem to be going anywhere fast, this is hugely important, due to the rocky recent history of EU-US data flows – following the invalidity of the Safe Harbor and subsequent Privacy Shield framework.
Above all, greater certainty is needed for the vast amount of companies that regularly exchange data between Europe and the US.
Then there’s the ADPPA – the American Data Privacy and Protection Act – a bill designed to regulate how organizations collect, process, manage, and even securely store personal information or “covered data.” The US does not yet have a comprehensive privacy law that creating such safeguards. The ADPPA has bipartisan support, but also faces opposition from privacy advocates and business groups.
After an initial flurry of excitement, how and when these laws will pass is up in the air. In the meantime, individual states are focusing on their own data laws.
“We have agreed to unprecedented protections for data privacy and security for our citizens. This new arrangement will enhance the Privacy Shield framework, promote growth and innovation in Europe and in the United States and help companies, both small and large, compete in the digital economy.”
Joe Biden, US President, March 25, 2022
Retroactively enforceable California Privacy Rights Act
Staying with US Bills, but moving specifically to California state now, and the CPRA comes into law after January 2023, technically speaking. But – and there’s a big but – companies need to be compliant retroactively. The second the law goes live, businesses can be fined for any non-compliance issues dating back to January 2022. Forewarned is definitely forearmed in this case.
Across the Atlantic…
118

To Europe and the EU Data Strategy. Its tagline is: ‘Making the EU a role model for a society empowered by data’. But this is so much more than the EU’s General Data Protection Regulation. It’s about the entire data landscape; a large regulatory umbrella under which the future of Europe’s data protection sits. Having said that, policymakers are far from finished in creating this broader regulation.
The new laws that will be incorporated into this holistic strategy will include, among others: The Data Act – aiming to create rights and responsibilities on how valuable forms of data are shared; The Data Governance Act – to create a “common European data space” and “single market for data” – boosting innovation while respecting the values of privacy; and the AI Act – the first law on AI by a major regulator, anywhere.
Importantly, none of these acts should be viewed in isolation. It’s a positive development that the EU is treating data as an asset (like physical infrastructure). Sewing all the various initiatives together in this way – data protection, governance, AI and also fair markets – is a savvy, cohesive approach, in my opinion.
However, it’s hard to know how effective this strategy will be when it comes to improving data development, given the EU currently lags behind on AI / ML. It remains to be seen if this will level the playing field, or create yet more red tape.
“People, businesses and organisations should be empowered to make better decisions based on insights from non-personal data, which should be available to all.”
European Commission
Source: https://commission.europa.eu/strategy-and-policy/priorities-2019-2024/europe-fit-digital-age/european-data-strategy_en
State of flux
113

In post-Brexit UK, the new UK-GDPR is nearly identical to the EU-GDPR. However, it is UK legislation independent of the EU. The UK has already performed a consultation process to see what data protection in the UK should look like in the future – and therefore new developments need to be monitored closely as they unfold.
114

First it was Apple’s move to block third-party cookies that conduct cross-site tracking on Safari, then Google announced they will do the same in 2023. But, with these changes making things difficult for advertisers and small publishers, what will adtech look like in the future?
Ever-changing laws…
109

Having passed its latest draft of the Personal Data Protection Bill over to the parliament in November 2021, the bill, now referred to as the Data Protection Bill or DPB as it now contains several provisions on non-personal data, has been pulled from consideration for parliament to draft entirely fresh language.
111

The Personal Data Protection Law (PDPL) is the first of its kind to be passed in Saudi Arabia. The protection rules were first published in September 2021 and they are due to come into effect in March 2023.
The Data Privacy Periodic Table is entirely unique to Calligo and is an ongoing project, contributed to by the entire industry. We encourage anyone who’s interested to get involved. I consider all comments when creating the next update.If you have any thoughts you’d like to share or want to discuss anything featured in more detail, you can contact me here.

Create an ethics-by-design approach for data
Our VP for Data Ethics & Governance, Sophie Chase-Borthwick, was recently part of a panel – the PICCASO Special Interest Group. Sophie joined William Malcolm (Privacy Legal Director at Google), Radha Gohil (Data Ethics Strategy Lead at Shell), and Anne Woodley (Security Specialist at Microsoft) in untangling what data ethics actually means and how best to support it. Here we look at this in more detail.